
K-MOOC 1주차 머신러닝 빅데이터 분석
K-MOOC 머신러닝 빅데이터 분석 1주차
1차시 머신러닝 필수 개념
머신러닝 : 컴퓨터가 스스로 학습을 해나가는 것
- 컴퓨터가 스스로 학습을 해서 어떠한 데이터를 주면 컴퓨터가 스스로 분류, 클러스터링 또는 여러 가지 방법으로 데이터를 처리하는 방법
1. 지도학습
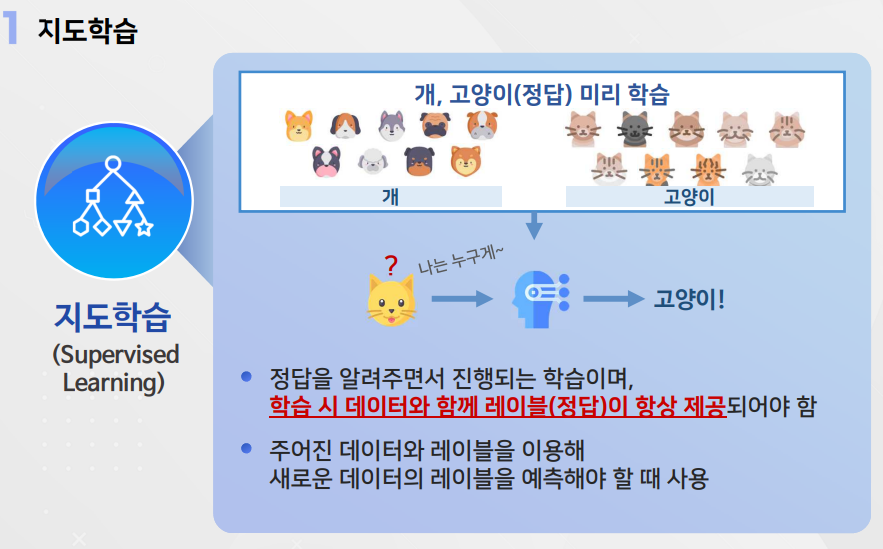
장점 : 손쉽게 모델의 성능을 평가할 수 있음
단점 : 레이블이 없는 데이터는 레이블을 달기 위해 많은 시간을 투자해야 하는 단점 존재
대표적인 예 : 분류, 회귀
2. 비지도 학습
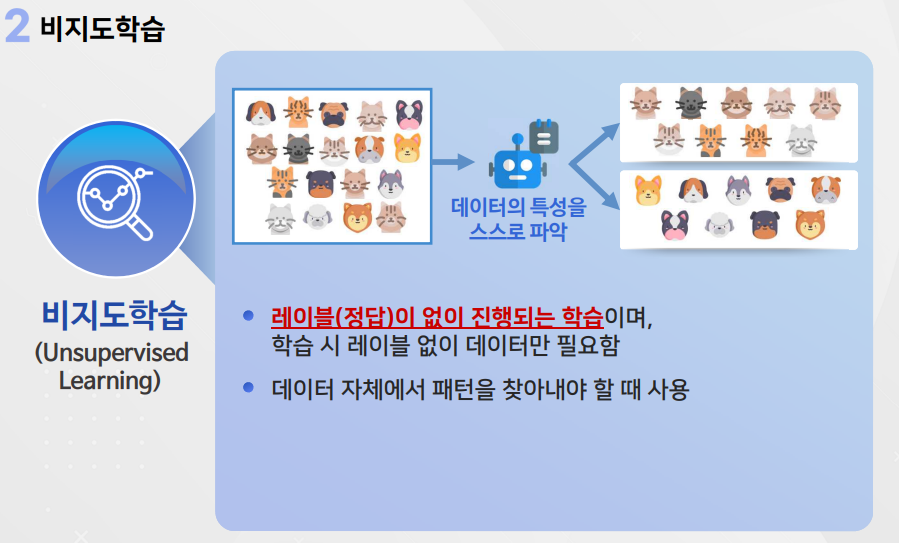
장점 : 별도로 레이블을 제공할 필요가 없으므로 시간 절약 가능
단점 : 레이블이 없으므로 모델의 성능을 평가하는 데 다소 어려움이 있음
대표적인 예 : 클러스터링, 차원 축소(PCA)
머신러닝 종류

1. 분류

2. 회귀

3. 분류와 회귀의 비교
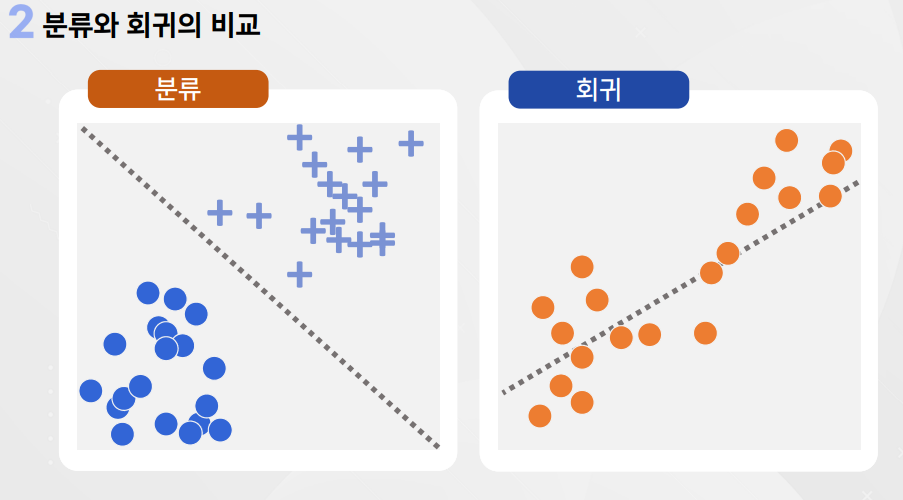

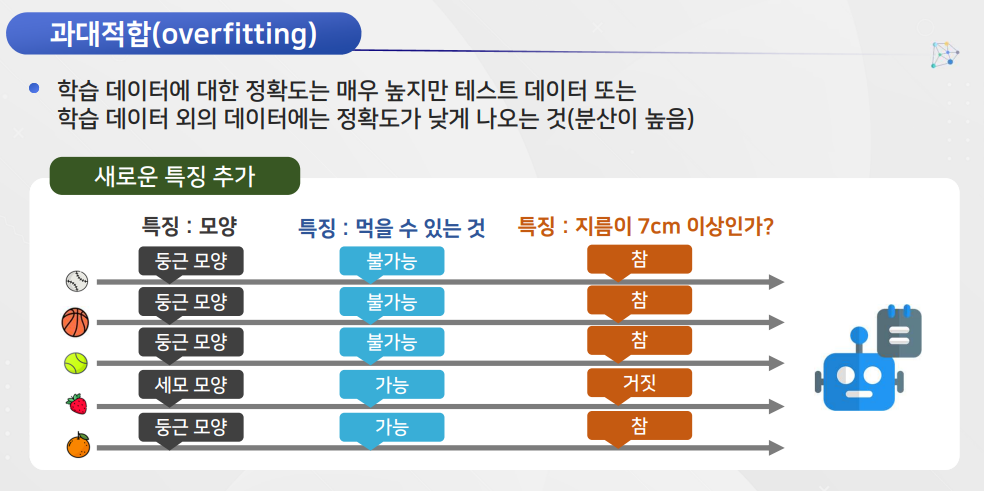
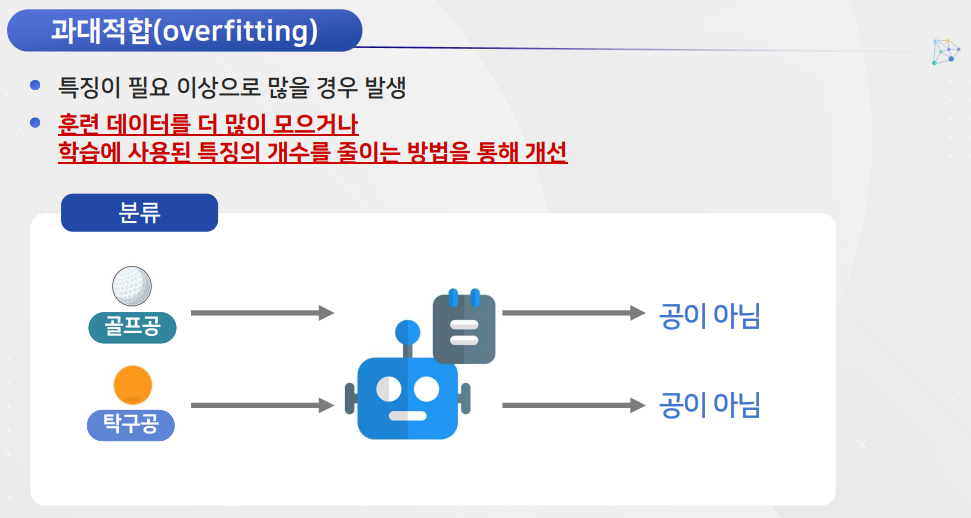
과소적합


과대적합
2차시 Numpy와 Pandas 활용하기

여기서 부턴 실습
Numpy
배열 만들기 및 초기화
import numpy as np
data = np.array([1,2,3,4,5,6])
data_2d = np.array([[1,2,3],[4,5,6]])
data_random = np.random.randn(2,3)
data_zeros = np.zeros(5)
data_ones = np.ones((2,3))
print(data)
print(data_2d)
print(data_2d.shape)
print(data_random)
print(data_zeros)
print(data_ones)
[1 2 3 4 5 6]
[[1 2 3]
[4 5 6]]
(2, 3)
[[ 0.59176955 -0.62082206 -0.62123606]
[ 0.8029205 -0.9723225 -1.57319348]]
[0. 0. 0. 0. 0.]
[[1. 1. 1.]
[1. 1. 1.]]
배열의 요소 추출
data = np.array([[1,2,3],
[4,5,6],
[7,8,9]])
print(data)
print(data[0][1])
print(data[0][1:])
data[0] = 100
print(data)
data[:] = 300
print(data)
[[1 2 3]
[4 5 6]
[7 8 9]]
2
[2 3]
[[100 100 100]
[ 4 5 6]
[ 7 8 9]]
[[300 300 300]
[300 300 300]
[300 300 300]]
배열의 산술 연산
data= np.array([[5,7,9],
[-7,-6,19],
[6,8.9,11]])
data_2 = data * 2
data_3 = data + 3
print(data)
print(data_2)
print(data_3)
print(data > data_2)
[[ 5. 7. 9. ]
[-7. -6. 19. ]
[ 6. 8.9 11. ]]
[[ 10. 14. 18. ]
[-14. -12. 38. ]
[ 12. 17.8 22. ]]
[[ 8. 10. 12. ]
[-4. -3. 22. ]
[ 9. 11.9 14. ]]
[[False False False]
[ True True False]
[False False False]]
배열의 통계 메소드
data= np.array([[5,7,9], [-7,-6,19], [6,8.9,11]])
print(data)
print(data.sum())
print(data.mean())
print(data.max())
print(data.min())
print(data.max(axis=0))
index_1 = np.argmax(data, axis=0)
print(index_1)
[[ 5. 7. 9. ]
[-7. -6. 19. ]
[ 6. 8.9 11. ]]
52.9
5.877777777777777
19.0
-7.0
[ 6. 8.9 19. ]
[2 2 1]
Pandas

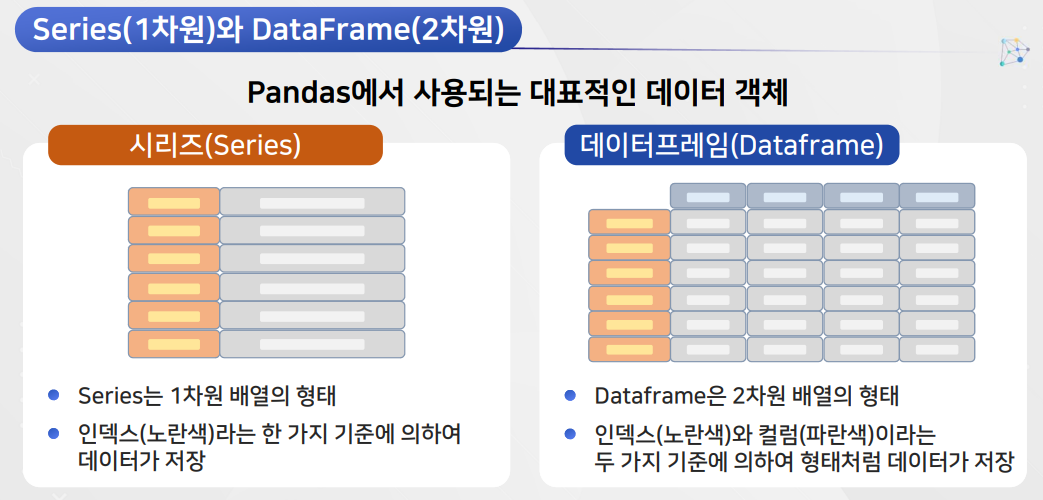
실습
Series 객체 생성 및 인덱스 설정
import pandas as pd
obj = pd.Series([10,20,30,40,50])
obj_2 = pd.Series([10,20,30,40,50],
index=['a','b','c','d','e'])
print(obj)
print(obj.index)
print(obj.values)
print(obj[1])
print(obj_2)
print(obj_2[['a','e']])
print(obj_2[1:3])
0 10
1 20
2 30
3 40
4 50
dtype: int64
RangeIndex(start=0, stop=5, step=1)
[10 20 30 40 50]
20
a 10
b 20
c 30
d 40
e 50
dtype: int64
a 10
e 50
dtype: int64
b 20
c 30
dtype: int64
객체의 연산과 조건식
obj = pd.Series([10,20,30,40])
print(obj * 10)
print('-' * 30)
print(obj >= 20)
0 100
1 200
2 300
3 400
dtype: int64
------------------------------
0 False
1 True
2 True
3 True
dtype: bool
Series 객체와 딕셔너리
data = pd.Series({'유재석':35,'박명수':60,'태진아':85},
index=['유재석','박명수','태진아','정형돈','하하'])
data['정형돈']=52
print(data)
print(data[3])
유재석 35.0
박명수 60.0
태진아 85.0
정형돈 52.0
하하 NaN
dtype: float64
52.0
DataFrame 객체 생성 및 인덱스 설정
data = {'이름':['유재석','박명수','정형돈','하하'],
'나이':[35,60,52,38],
'키':[180,175,160,150]}
frame = pd.DataFrame(data)
frame_2 = pd.DataFrame(data,
columns=['이름','나이','키','몸무게'])
print(data)
print(frame)
print(frame_2)
print(frame.head(2))
print(frame.tail(2))
{'이름': ['유재석', '박명수', '정형돈', '하하'], '나이': [35, 60, 52, 38], '키': [180, 175, 160, 150]}
이름 나이 키
0 유재석 35 180
1 박명수 60 175
2 정형돈 52 160
3 하하 38 150
이름 나이 키 몸무게
0 유재석 35 180 NaN
1 박명수 60 175 NaN
2 정형돈 52 160 NaN
3 하하 38 150 NaN
이름 나이 키
0 유재석 35 180
1 박명수 60 175
이름 나이 키
2 정형돈 52 160
3 하하 38 150
DataFrame 요소 추출하기
data = {'이름':['유재석','박명수','정형돈','하하'],
'나이':[35,60,52,38],
'키':[180,175,160,150]}
frame = pd.DataFrame(data, index=['첫째','둘째','셋째','넷째'])
print(frame)
print(frame.loc['둘째','이름'])
print(frame.loc['넷째',['나이','키']])
print('-' * 30)
print(frame.iloc[2,0])
print(frame.iloc[3,:2])
print(frame.iloc[:,[0,2]])
이름 나이 키
첫째 유재석 35 180
둘째 박명수 60 175
셋째 정형돈 52 160
넷째 하하 38 150
박명수
나이 38
키 150
Name: 넷째, dtype: object
------------------------------
정형돈
이름 하하
나이 38
Name: 넷째, dtype: object
이름 키
첫째 유재석 180
둘째 박명수 175
셋째 정형돈 160
넷째 하하 150
합계와 평균/정렬하기
data = {'이름':['유재석','박명수','정형돈','하하'],
'나이':[35,60,52,38],
'키':[180,175,160,150]}
frame = pd.DataFrame(data)
frame_2 = frame.iloc[:,[1,2]]
rank = frame.sort_values(by=['나이'], ascending=False)
total = frame_2.sum(axis=0)
avg = frame_2.mean(axis=0)
print(frame_2)
print(rank)
print(total)
print(avg)
나이 키
0 35 180
1 60 175
2 52 160
3 38 150
이름 나이 키
1 박명수 60 175
2 정형돈 52 160
3 하하 38 150
0 유재석 35 180
나이 185
키 665
dtype: int64
나이 46.25
키 166.25
dtype: float64
3차시 Seaborn 활용하기

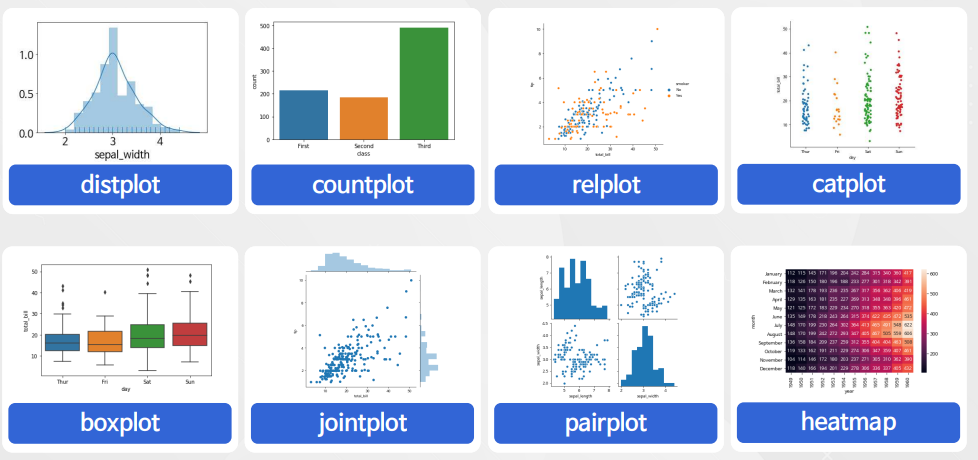
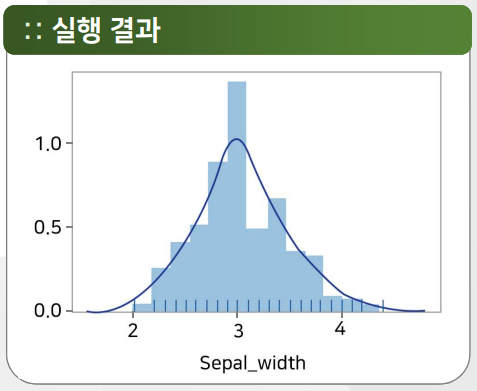
distplot / histplot
import seaborn as sns
iris = sns.load_dataset("iris")
# sns.distplot(iris["sepal_width"],hist=True,kde=True,rug=True)
sns.histplot(iris["sepal_width"])
<AxesSubplot:xlabel='sepal_width', ylabel='Count'>
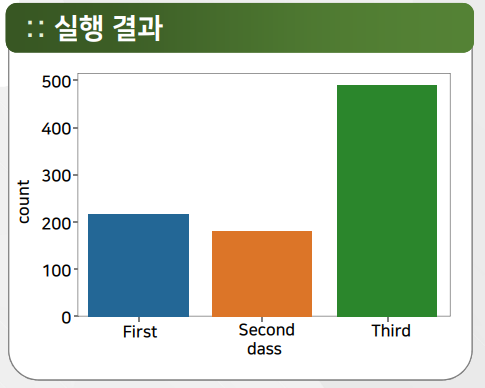
countplot
titanic = sns.load_dataset("titanic")
sns.countplot(x="class", data=titanic)
<AxesSubplot:xlabel='class', ylabel='count'>
relplot
tips = sns.load_dataset("tips")
sns.relplot(x="total_bill",y="tip",
hue="smoker",data=tips,
kind="line")
sns.relplot(x="total_bill",y="tip",
hue="smoker",
col="time",data=tips)
<seaborn.axisgrid.FacetGrid at 0x272c331beb8>
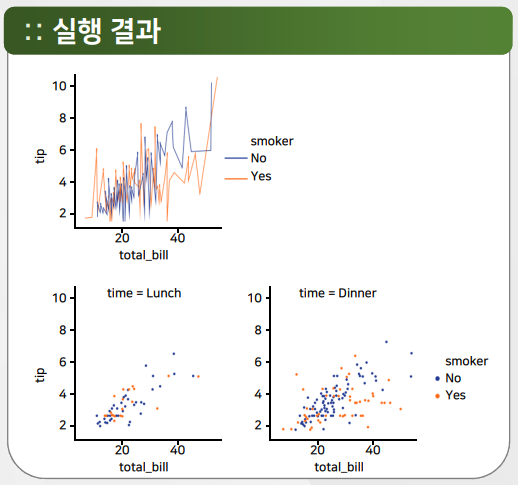
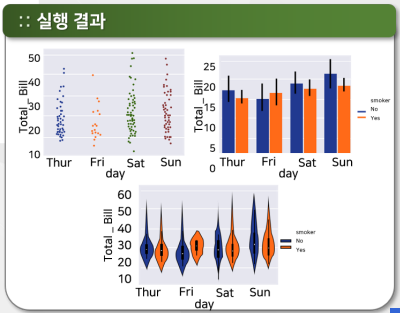
catplot
import matplotlib.pyplot as plt
tips = sns.load_dataset("tips")
sns.catplot(x="day",y="total_bill", data=tips)
sns.catplot(x="day",y="total_bill", hue="smoker",
kind="bar", data=tips)
sns.catplot(x="day", y="total_bill", hue="smoker",
kind="violin", data=tips)
plt.figure(figsize=(8,6))
<Figure size 576x432 with 0 Axes>
<Figure size 576x432 with 0 Axes>
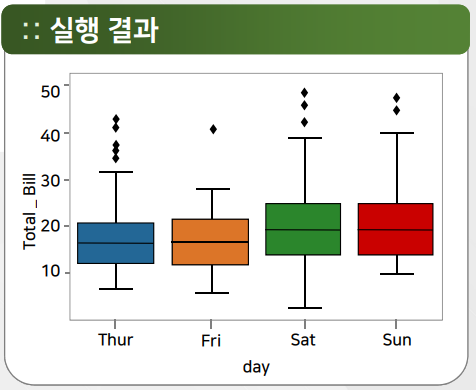
boxplot
tips = sns.load_dataset("tips")
sns.boxplot(x="day", y="total_bill", data=tips)
<AxesSubplot:xlabel='day', ylabel='total_bill'>

joinplot
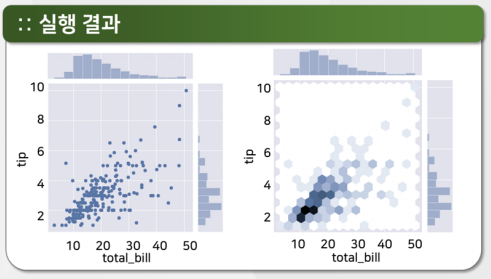
tips = sns.load_dataset("tips")
sns.jointplot(x="total_bill", y="tip", data=tips)
sns.jointplot(x="total_bill", y="tip", data=tips, kind="hex")
<seaborn.axisgrid.JointGrid at 0x272c49f6b70>


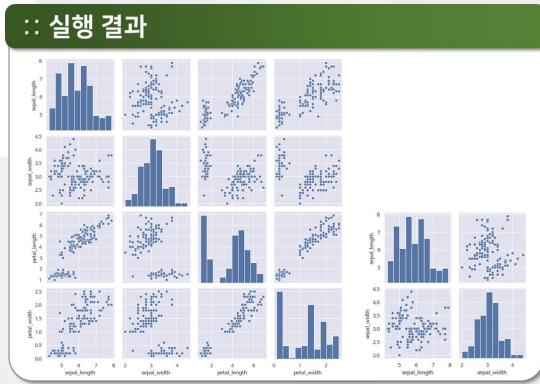
pairplot
iris = sns.load_dataset("iris")
sns.pairplot(iris)
sns.pairplot(iris, vars=["sepal_length", "sepal_width"])
<seaborn.axisgrid.PairGrid at 0x272c367da20>


heatmap
flights = sns.load_dataset('flights')
flight = flights.pivot('month', 'year', 'passengers')
sns.heatmap(flight, annot=True, fmt="d")
<AxesSubplot:xlabel='year', ylabel='month'>

Leave a comment