pixel1 pixel2 pixel3 pixel4 ... pixel781 pixel782 pixel783 pixel784
0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
3 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
4 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
... ... ... ... ... ... ... ... ... ...
9995 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
9996 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
9997 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
9998 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
9999 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
[10000 rows x 784 columns]
(10000, 784)
0 5
1 0
2 4
3 1
4 9
..
9995 5
9996 8
9997 6
9998 9
9999 7
Name: class, Length: 10000, dtype: category
Categories (10, object): ['0', '1', '2', '3', ..., '6', '7', '8', '9']
(10000,)
의사결정트리 예측 정확도: 0.8005
랜덤 포레스트 예측 정확도: 0.9380
rf_param_grid ={
'n_estimators' : [100, 110, 120],
'min_samples_leaf' : [1, 2, 3],
'min_samples_split' : [2, 3, 4]
}
rf_clf = RandomForestClassifier(random_state = 0)
grid = GridSearchCV(rf_clf, param_grid = rf_param_grid, scoring='accuracy', n_jobs=1)
grid.fit(X_train, y_train)
GridSearchCV(estimator=RandomForestClassifier(random_state=0), n_jobs=1,
param_grid={'min_samples_leaf': [1, 2, 3],
'min_samples_split': [2, 3, 4],
'n_estimators': [100, 110, 120]},
scoring='accuracy')
최고 평균 정확도 : 0.9474
{'min_samples_leaf': 1, 'min_samples_split': 2, 'n_estimators': 100}
np.random.seed(5)
mnist = datasets.load_digits()
features, labels = mnist.data, mnist.target
X_train,X_test,y_train,y_test=train_test_split(features,labels,test_size=0.2)
dtree = tree.DecisionTreeClassifier(
criterion="gini", max_depth=8, max_features=32)
dtree = dtree.fit(X_train, y_train)
dtree_predicted = dtree.predict(X_test)
knn = KNeighborsClassifier(n_neighbors=299).fit(X_train, y_train)
knn_predicted = knn.predict(X_test)
svm = SVC(C=0.1, gamma=0.003,
probability=True).fit(X_train, y_train)
svm_predicted = svm.predict(X_test)
print("[accuarcy]")
print("d-tree: ", accuracy_score(y_test, dtree_predicted))
print("knn : ", accuracy_score(y_test, knn_predicted))
print("svm : ", accuracy_score(y_test, svm_predicted))
[accuarcy]
d-tree: 0.7916666666666666
knn : 0.8944444444444445
svm : 0.8916666666666667
[[0.0020036 0.00913495 0.00860886 0.00431856 0.0047931 0.8975483
0.0019513 0.01046554 0.04855539 0.0126204 ]
[0.00290208 0.01165787 0.86869732 0.00809384 0.00503728 0.01857273
0.00301187 0.00945009 0.05716773 0.0154092 ]]
voting_model = VotingClassifier(estimators=[
('Decision_Tree', dtree), ('k-NN', knn), ('SVM', svm)],
weights=[1,1,1], voting='hard')
voting_model.fit(X_train, y_train)
hard_voting_predicted = voting_model.predict(X_test)
accuracy_score(y_test, hard_voting_predicted)
voting_model = VotingClassifier(estimators=[
('Decision_Tree', dtree), ('k-NN', knn), ('SVM', svm)],
weights=[1,1,1], voting='soft')
voting_model.fit(X_train, y_train)
soft_voting_predicted = voting_model.predict(X_test)
accuracy_score(y_test, soft_voting_predicted)
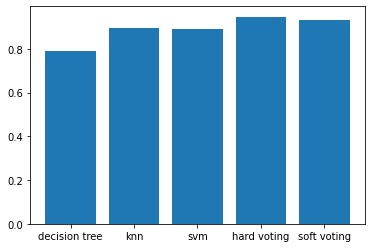
x = np.arange(5)
plt.bar(x, height= [accuracy_score(y_test, dtree_predicted),
accuracy_score(y_test, knn_predicted),
accuracy_score(y_test, svm_predicted),
accuracy_score(y_test, hard_voting_predicted),
accuracy_score(y_test, soft_voting_predicted)])
plt.xticks(x, ['decision tree','knn','svm','hard voting','soft voting']);







Leave a comment