
K-MOOC 5주차 머신러닝으로 군집화하기
1. K-평균 알고리즘 이해하기
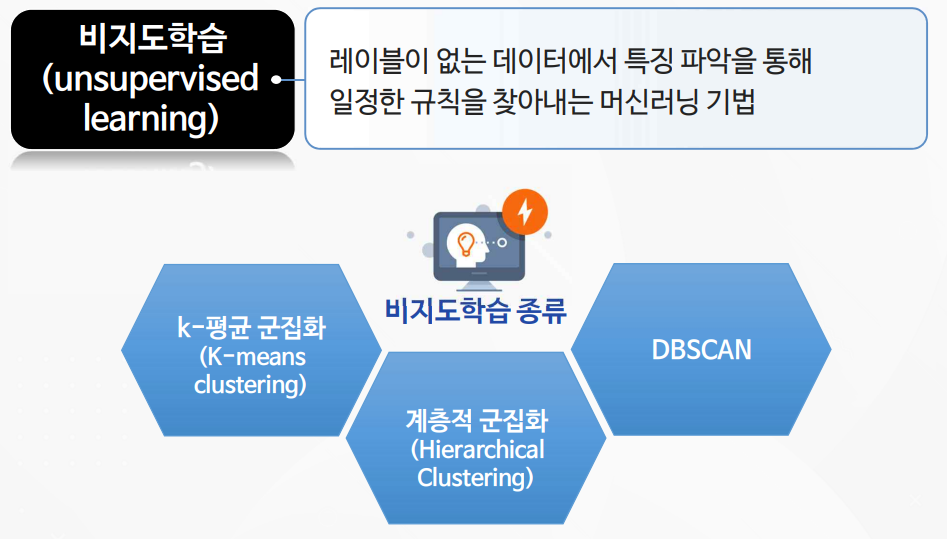
1-1. 비지도학습의 이해

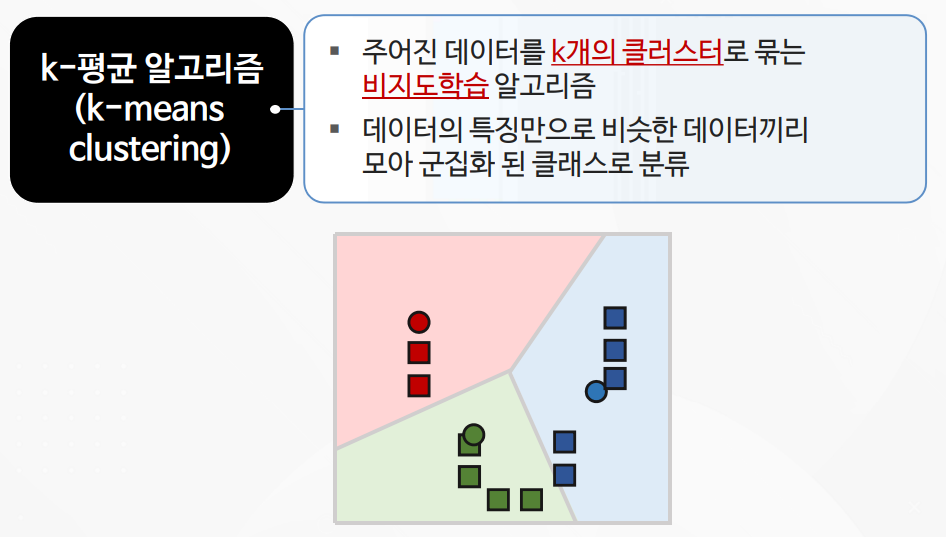
1-2. K-평균 알고리즘
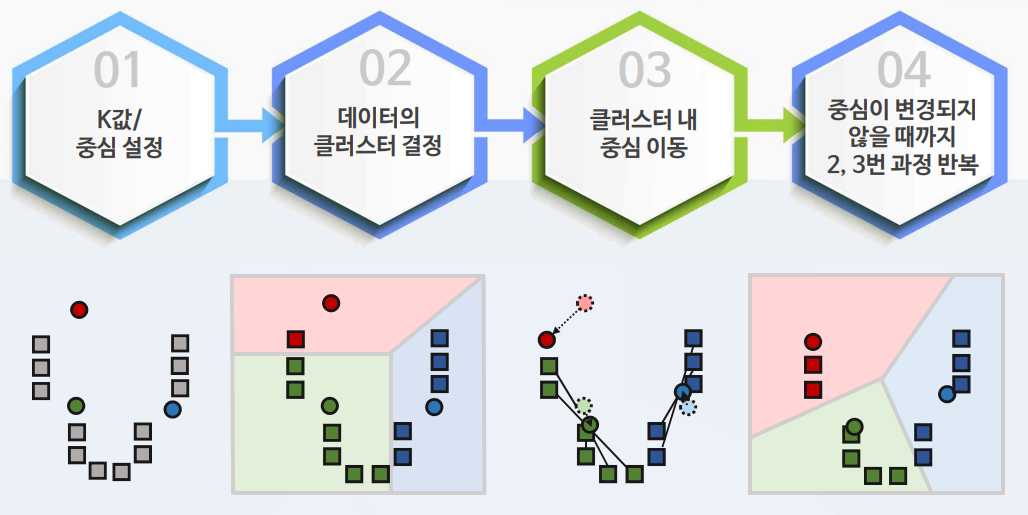
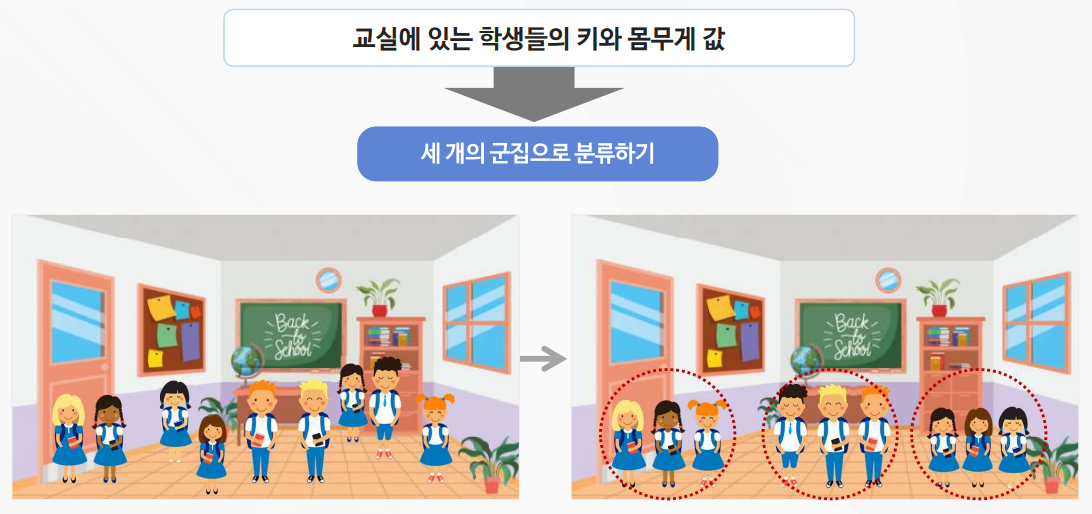
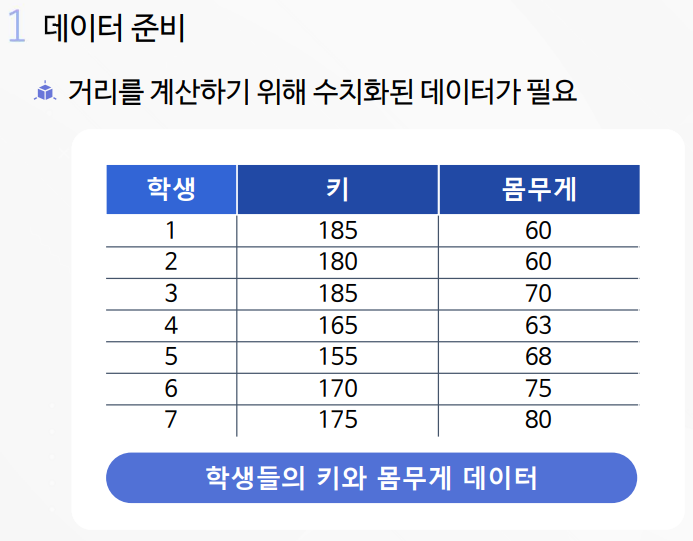

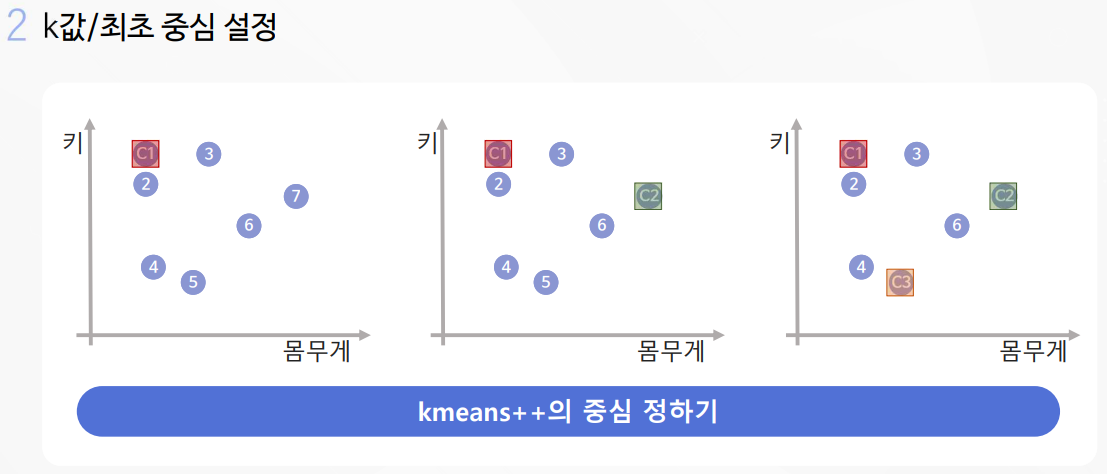
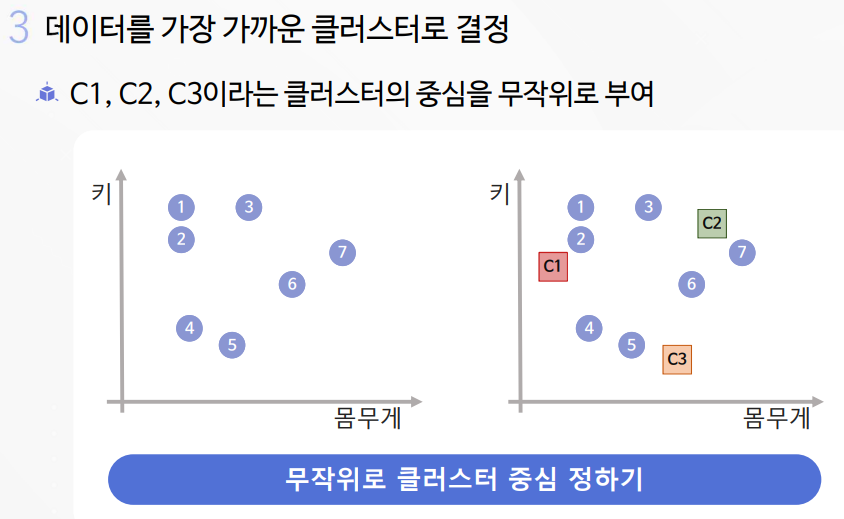
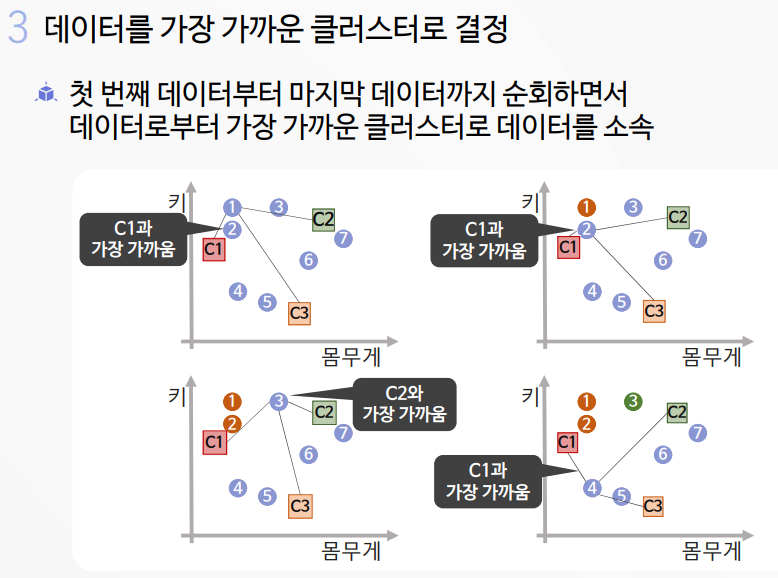
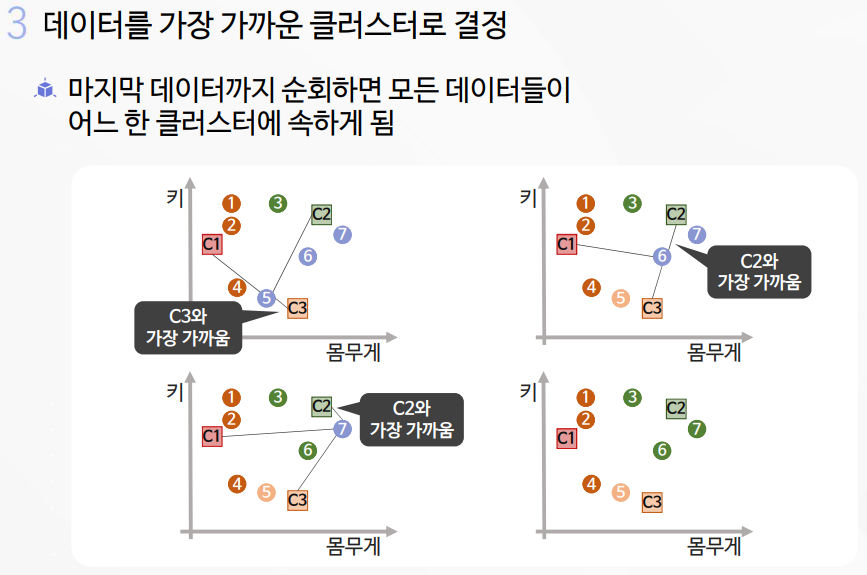
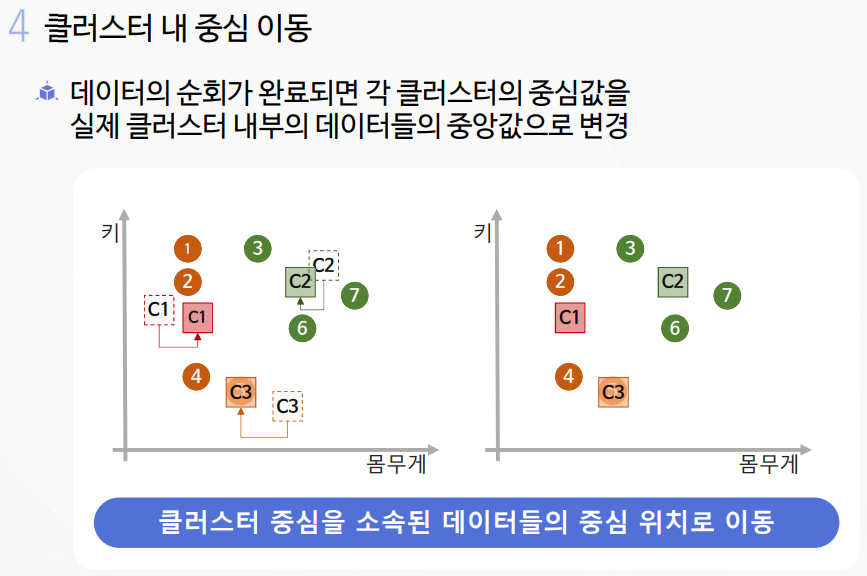
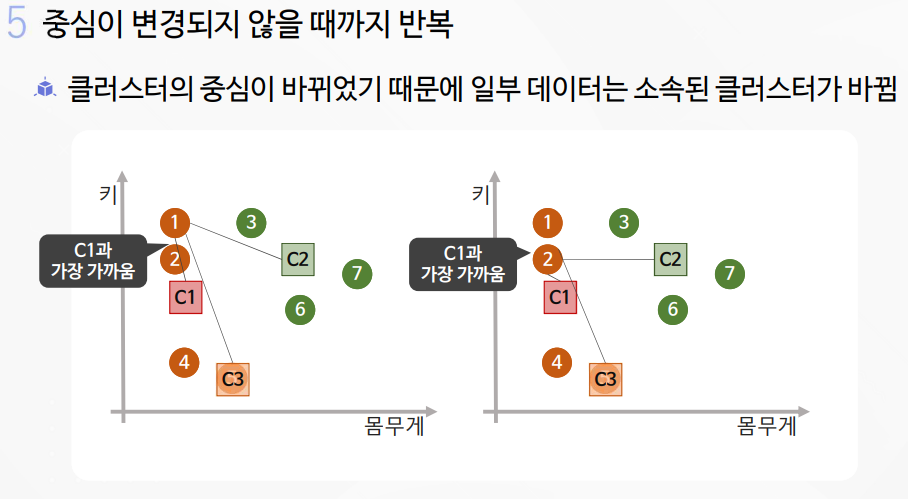
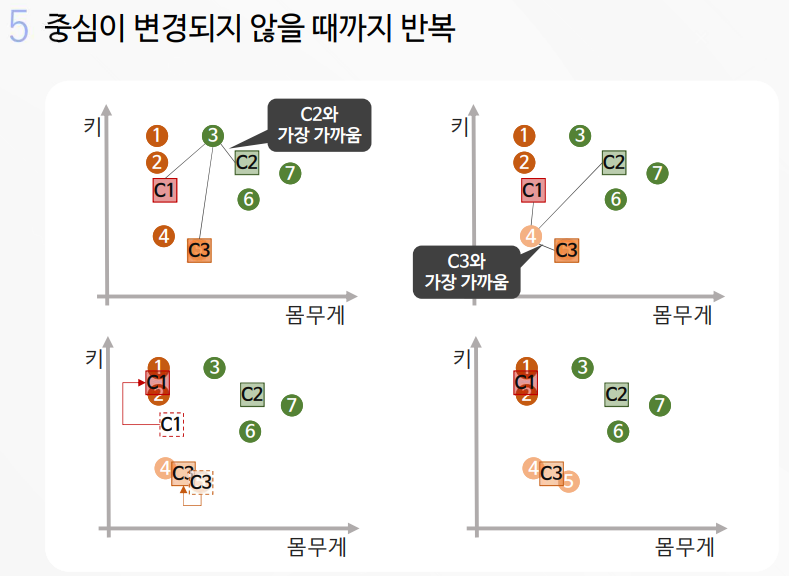
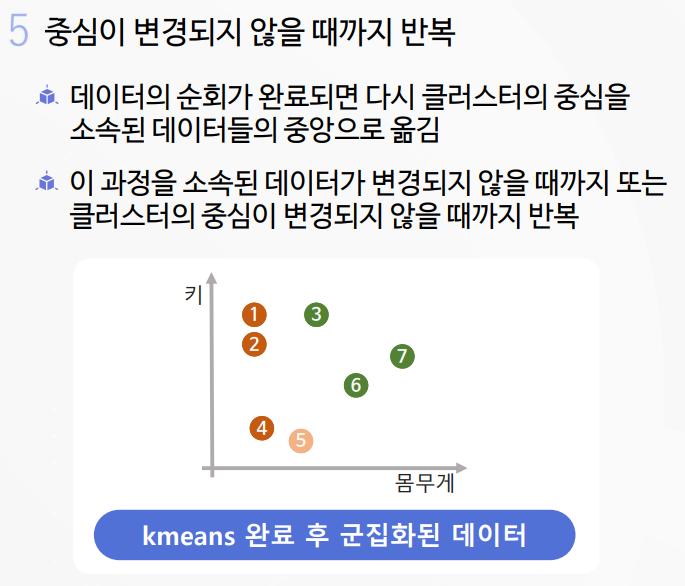
2-1. K-평균 알고리즘 실습

# 라이브러리 import
import pandas as pd
from sklearn.cluster import KMeans
import seaborn as sns
# 데이터셋 로드
filename = '/gdrive/My Drive/kmeans.csv'
#사이즈 코리아(https://sizekorea.kr/)
#2015년 남/녀 신장과 몸무게 데이터(500명)
# 데이터 탐색
df = pd.read_csv(filename)
print(df.head())
print(df.shape)

# 데이터 시각화하여 확인하기
sns.lmplot(x='height', y='weight',
data=df,
fit_reg= True,
scatter_kws={"s": 50})
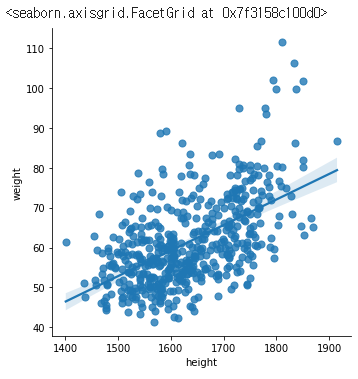
# 클러스터링 수행
data_points = df.values
kmeans = KMeans(n_clusters=3).fit(data_points)
kmeans.labels_[:10]
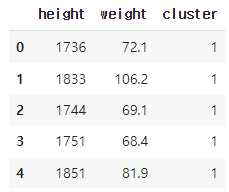
df['cluster'] = kmeans.labels_
df.head()
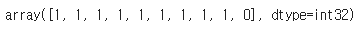
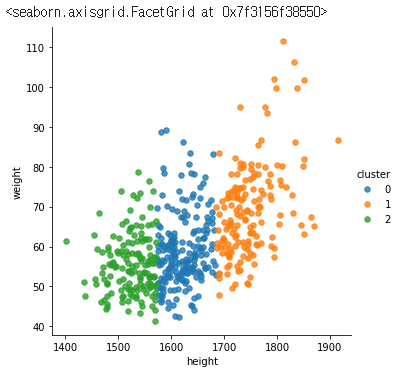
# 결과 시각화
sns.lmplot(x='height',y='weight',
data=df,
fit_reg=False,
scatter_kws={"s": 30},
hue='cluster')
2-2. IRIS 분류 실습
# 라이브러리 import
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
# 데이터셋 로드 및 확인
iris = load_iris()
data = iris.data[:,[0,1]]
data[:10]

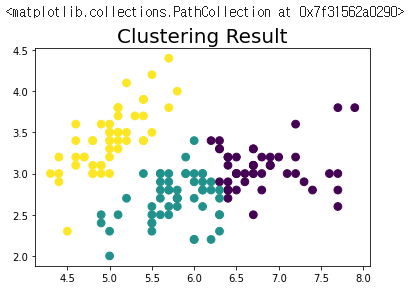
# 클러스터링 수행 및 시각화
kmeans_iris = KMeans(n_clusters=3).fit(data)
labels = kmeans_iris.labels_
plt.title('Clustering Result', fontsize=20)
plt.scatter(data[:,0], data[:,1], c=labels, s=60)
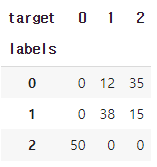
# 분류 정확도 확인
target = iris.target
df = pd.DataFrame({'labels': labels, 'target': target})
ct = pd.crosstab(df['labels'], df['target'])
ct
# 최적의 K값 찾기
num_clusters = list(range(2, 9))
inertias = []
for i in num_clusters:
model = KMeans(n_clusters=i)
model.fit(data)
inertias.append(model.inertia_)
plt.plot(num_clusters, inertias, '-o')
plt.xlabel('Num. of Clusters')
plt.ylabel('Inertia')
plt.show()

3. 계층적 군집화

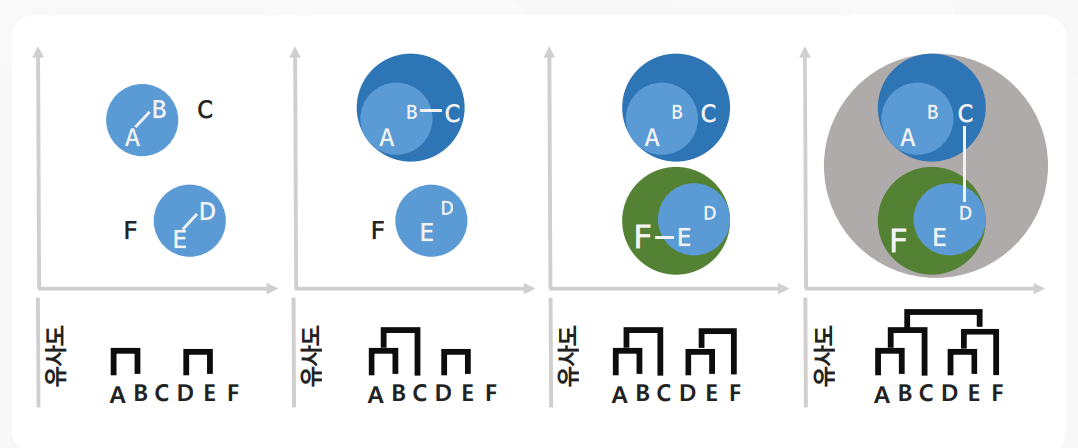
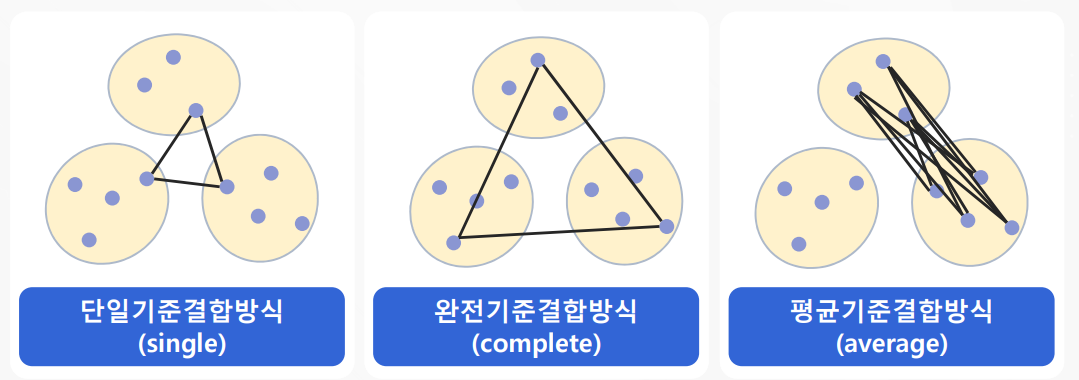


# 라이브러리 import & 데이터 로드
from scipy.cluster.hierarchy import linkage, dendrogram
from scipy.cluster.hierarchy import fcluster
from sklearn import datasets
import matplotlib.pyplot as plt
import pandas as pd
iris = datasets.load_iris()
labels = pd.DataFrame(iris.target)
labels.columns=['labels']
data = pd.DataFrame(iris.data)
data = pd.concat([data,labels],axis=1)
data.head()

# 클러스터링 수행
merge = linkage(data, method='complete') # single, average, complete, ward
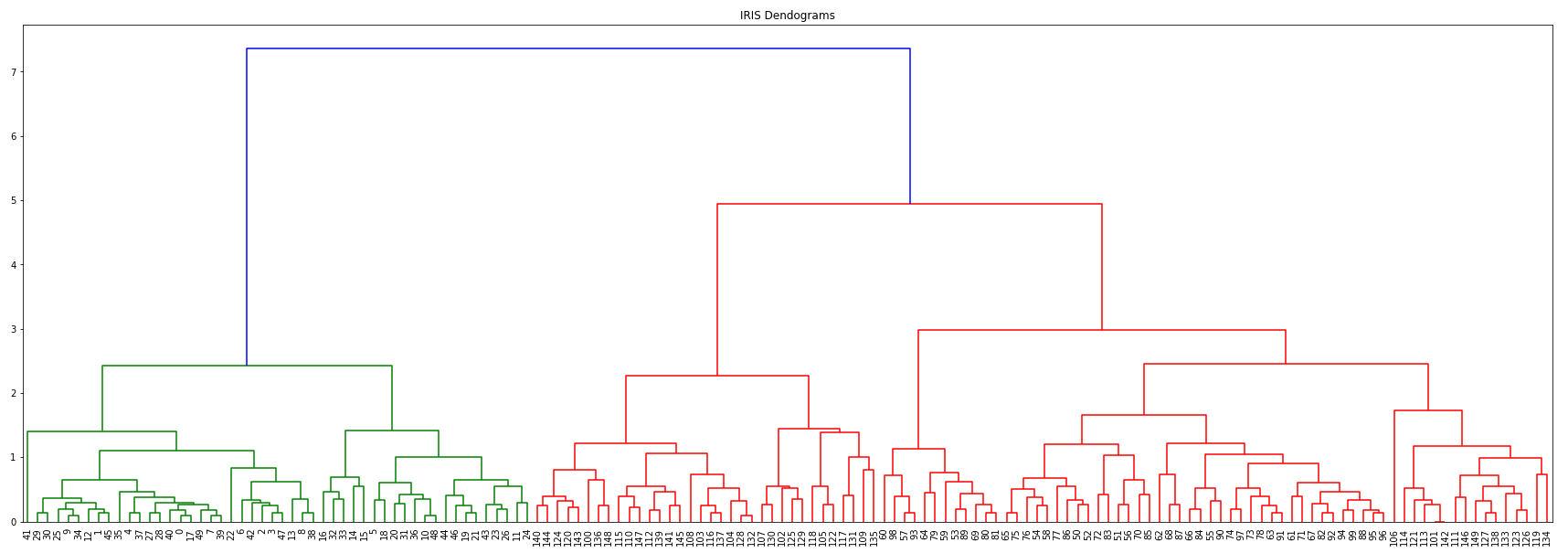
plt.figure(figsize=(30,10))
plt.title("IRIS Dendograms")
dendrogram(merge,
leaf_rotation=90,
leaf_font_size=10)
plt.show()
# 클러스터 자르기
cut = fcluster(merge, t=3, criterion='distance')
cut

# 분류 결과 확인
labels = data['labels']
labels

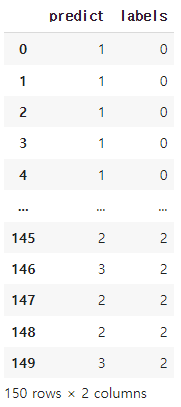
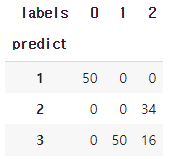
df = pd.DataFrame({'predict':cut, 'labels':labels})
df
ct = pd.crosstab(df['predict'], df['labels'])
ct
Leave a comment