
강화 학습 Chapter 1. 입문하기
1. 지도학습과 강화학습
자전거를 배우는 아이가 있습니다.

누군가의 도움으로 학습을 하는 경우와 혼자서 시행착오를 통해서 배우는 경우
총 두 가지의 경우가 있다.
여기서 혼자서 시행착오를 한다면 망할 수 있지않을까? 라는 의문이 들게 된다.
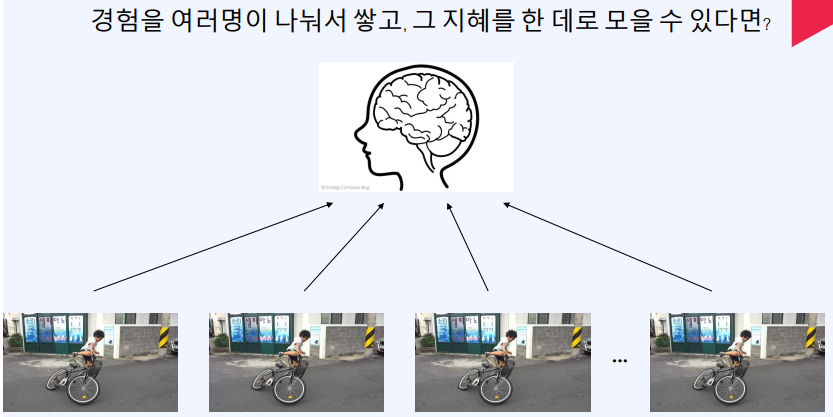
예를 들어 몸을 100개로 나누고 각각의 경험을 공유한다 가정하면
각각의 시행착오를 통해 얻은 깨달음이 공유가 될것이고 시간도 적게 걸린다.
이러한 병렬적 특징을 가진다. 하지만 지도학습 또한 병렬적 특징이 있다.
또한 지도학습은 모아진 데이터를 가지고 학습 하는 방식이면
강화학습은 데이터를 쌓으면서 학습하는 과정입니다. 그래서 병렬성이 중요합니다.
결과적으로 강화학습을 정의하면 “순차적 의사 결정 문제에서 누적 보상을 최적화 하기 위해 시행 착오를 통해 행동을 교정하는 과정” 쉽게 말해 “일단 해보고, 결과가 좋으면 더, 결과가 안좋으면 덜 하는 과정” 입니다.
2. 순차적 의사 결정 문제
변화하는 상황(state)에서 행동(action)을 통해서 의사결정을 내릴수있음. 순차적 의사 결정은 우리 주변의 흔한 문제이다.
순차적 의사 결정 문제의 예시
- 주식
- 게임

- 운전

3. 보상(Reward)
3-1. 리워드의 특징
- 어떻게 X, 얼마나 O
- 리워드를 통해서 어떻게 해야하는지 직접적으로 알기는 어렵다.
- 그저 결과가 좋았는지/안좋았는지
- 좋았다면 얼마나 좋았는지를 알려준다.
- 스칼라 값
- 1차원 실수 값 하나로 주어진다.
- 결과가 좋았으면 더 큰 값, 결과가 안좋았으면 더 작은 값
- 이 값의 총합을 최대화 하는 것이 강화 학습의 목적
- 희소하고 지연될 수 있다.
- 보상이 조금씩 주어진다면 아주 행복하다.
- 어떤 행동이 결과에 책임이 있었는지 알 수 있기 때문
- 하지만 현실은 그렇지 않다.
- 희소할수도(sparse)
- 지연될수도(delayed)
- 액션의 책임사유를 묻기가 힘들어진다.
3-2. Reward Hypothesis
- 강화학습은 Reward Hypothesis에 기반
Reward Hypothesis
-
모든 목표는 expected cumulative reward(누적 보상)를 최대화 하는 것으로 표현할 수 있다.
-
Reward 설계의 예시
- 바둑을 잘 둔다.
- 이기면 1, 지면 0 으로 최적화 하여 모두를 이기게 하는 것
- 운전을 잘 한다.
- 도착까지 걸린 시간, 안전한 운전, 주변 피해 여부 등등 고려할게 많아 까다로움
- 바둑을 잘 둔다.
4. 에이전트와 환경
4-1. 에이전트
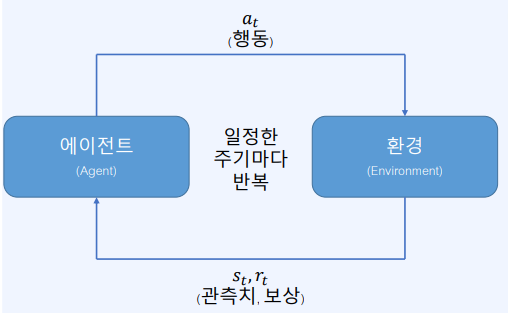
- 환경으로부터 현재 시점 $t$에서의 환경에 대한 정보 $S_t$와 보상 $r_t$를 받음
- $S_t$를 바탕으로 어떤 행동을 해야 할지 결정
- 결정된 행동 $a_t$를 환경으로 보냄
- 행동(action)을 선택하는 것이 제 1목표이다.
4-2. 환경
- 에이전트로부터 받은 행동 $a_t$를 통해서 상태 변화를 일으킴
- 그 결과 상태는 $S_t$ -> $S_{t+1}$로 바뀜
- 에이전트에게 줄 보상 $r_{t+1}$도 함께 계산
- $S_{t+1}$와 $r_{t+1}$을 에이전트에게 전달
4-3. 에이전트의 종류
에이전트는 행동을 선택하는 것이 첫번째 목표이다. 다음 종류는 어떻게 행동을 선택할것인가에 따라 나뉘게 된다.
- Value Based
- 할수있는 action이 5개가 있다고 가정
- 각각의 action value를 계산하여 가장 높은 값을 정하고 선택하여 수행하는 것
- Policy Based
- action을 어떻게 선택할지 정책을 설정
- 각 action들에 대한 확률분포로 표현해서 그 확률 기반으로 action을 샘플링해서 움직이는 것
- Actor Critic
- action 선택은 Policy 기반의 Actor가 결정
- 어떻게 학습할지는 Value 기반의 Critic이 결정
5. Exploitation vs Exploration
Exploitation : 아는 것을 바탕으로 최선을 다 하는것
Exploration : 정보를 더 모으고자 모험적 행동을 해보는 것
예시
식당 고르기
Leave a comment